Building a Similar Movies Recommendation System
Why?
I recently came across a movie/tv-show recommender, couchmoney.tv. I loved it. I decided that I wanted to build something similar, so I could tinker with it as much as I wanted.
I also wanted a recommendation system I could use via a REST API. Although I have not included that part in this post, I did eventually create it.
How?
By measuring the cosine of the angle between two vectors, you can get a value in the range [0,1] with 0 meaning no similarity. Now, if we find a way to represent information about movies as a vector, we can use cosine similarity as a metric to find similar movies.
As we are recommending just based on the content of the movies, this is called a content based recommendation system.
Data Collection
Trakt exposes a nice API to search for movies/tv-shows. To access the API, you first need to get an API key (the Trakt ID you get when you create a new application).
I decided to use SQL-Alchemy with a SQLite backend just to make my life easier if I decided on switching to Postgres anytime I felt like.
First, I needed to check the total number of records in Trakt’s database.
import requests
import os
trakt_id = os.getenv("TRAKT_ID")
api_base = "https://api.trakt.tv"
headers = {
"Content-Type": "application/json",
"trakt-api-version": "2",
"trakt-api-key": trakt_id
}
params = {
"query": "",
"years": "1900-2021",
"page": "1",
"extended": "full",
"languages": "en"
}
res = requests.get(f"{api_base}/search/movie",headers=headers,params=params)
total_items = res.headers["x-pagination-item-count"]
print(f"There are {total_items} movies")
There are 333946 movies
First, I needed to declare the database schema in (database.py):
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy import Table, Column, Integer, String, MetaData, ForeignKey, PickleType
from sqlalchemy import insert
from sqlalchemy.orm import sessionmaker
from sqlalchemy.exc import IntegrityError
meta = MetaData()
movies_table = Table(
"movies",
meta,
Column("trakt_id", Integer, primary_key=True, autoincrement=False),
Column("title", String),
Column("overview", String),
Column("genres", String),
Column("year", Integer),
Column("released", String),
Column("runtime", Integer),
Column("country", String),
Column("language", String),
Column("rating", Integer),
Column("votes", Integer),
Column("comment_count", Integer),
Column("tagline", String),
Column("embeddings", PickleType)
)
# Helper function to connect to the db
def init_db_stuff(database_url: str):
engine = create_engine(database_url)
meta.create_all(engine)
Session = sessionmaker(bind=engine)
return engine, Session
In the end, I could have dropped the embeddings field from the table schema as I never got around to using it.
Scripting Time
from database import *
from tqdm import tqdm
import requests
import os
trakt_id = os.getenv("TRAKT_ID")
max_requests = 5000 # How many requests I wanted to wrap everything up in
req_count = 0 # A counter for how many requests I have made
years = "1900-2021"
page = 1 # The initial page number for the search
extended = "full" # Required to get additional information
limit = "10" # No of entires per request -- This will be automatically picked based on max_requests
languages = "en" # Limit to English
api_base = "https://api.trakt.tv"
database_url = "sqlite:///jlm.db"
headers = {
"Content-Type": "application/json",
"trakt-api-version": "2",
"trakt-api-key": trakt_id
}
params = {
"query": "",
"years": years,
"page": page,
"extended": extended,
"limit": limit,
"languages": languages
}
# Helper function to get desirable values from the response
def create_movie_dict(movie: dict):
m = movie["movie"]
movie_dict = {
"title": m["title"],
"overview": m["overview"],
"genres": m["genres"],
"language": m["language"],
"year": int(m["year"]),
"trakt_id": m["ids"]["trakt"],
"released": m["released"],
"runtime": int(m["runtime"]),
"country": m["country"],
"rating": int(m["rating"]),
"votes": int(m["votes"]),
"comment_count": int(m["comment_count"]),
"tagline": m["tagline"]
}
return movie_dict
# Get total number of items
params["limit"] = 1
res = requests.get(f"{api_base}/search/movie",headers=headers,params=params)
total_items = res.headers["x-pagination-item-count"]
engine, Session = init_db_stuff(database_url)
for page in tqdm(range(1,max_requests+1)):
params["page"] = page
params["limit"] = int(int(total_items)/max_requests)
movies = []
res = requests.get(f"{api_base}/search/movie",headers=headers,params=params)
if res.status_code == 500:
break
elif res.status_code == 200:
None
else:
print(f"OwO Code {res.status_code}")
for movie in res.json():
movies.append(create_movie_dict(movie))
with engine.connect() as conn:
for movie in movies:
with conn.begin() as trans:
stmt = insert(movies_table).values(
trakt_id=movie["trakt_id"], title=movie["title"], genres=" ".join(movie["genres"]),
language=movie["language"], year=movie["year"], released=movie["released"],
runtime=movie["runtime"], country=movie["country"], overview=movie["overview"],
rating=movie["rating"], votes=movie["votes"], comment_count=movie["comment_count"],
tagline=movie["tagline"])
try:
result = conn.execute(stmt)
trans.commit()
except IntegrityError:
trans.rollback()
req_count += 1
(Note: I was well within the rate-limit so I did not have to slow down or implement any other measures)
Running this script took me approximately 3 hours, and resulted in an SQLite database of 141.5 MB
Embeddings!
I did not want to put my poor Mac through the estimated 23 hours it would have taken to embed the sentences. I decided to use Google Colab instead.
Because of the small size of the database file, I was able to just upload the file.
For the encoding model, I decided to use the pretrained paraphrase-multilingual-MiniLM-L12-v2 model for SentenceTransformers, a Python framework for SOTA sentence, text and image embeddings.
I wanted to use a multilingual model as I personally consume content in various languages and some of the sources for their information do not translate to English.
As of writing this post, I did not include any other database except Trakt.
While deciding how I was going to process the embeddings, I came across multiple solutions:
Milvus - An open-source vector database with similar search functionality
FAISS - A library for efficient similarity search
Pinecone - A fully managed vector database with similar search functionality
I did not want to waste time setting up the first two, so I decided to go with Pinecone which offers 1M 768-dim vectors for free with no credit card required (Our embeddings are 384-dim dense).
Getting started with Pinecone was as easy as:
Signing up
Specifying the index name and vector dimensions along with the similarity search metric (Cosine Similarity for our use case)
Getting the API key
Installing the Python module (pinecone-client)
import pandas as pd
import pinecone
from sentence_transformers import SentenceTransformer
from tqdm import tqdm
database_url = "sqlite:///jlm.db"
PINECONE_KEY = "not-this-at-all"
batch_size = 32
pinecone.init(api_key=PINECONE_KEY, environment="us-west1-gcp")
index = pinecone.Index("movies")
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2", device="cuda")
engine, Session = init_db_stuff(database_url)
df = pd.read_sql("Select * from movies", engine)
df["combined_text"] = df["title"] + ": " + df["overview"].fillna('') + " - " + df["tagline"].fillna('') + " Genres:- " + df["genres"].fillna('')
# Creating the embedding and inserting it into the database
for x in tqdm(range(0,len(df),batch_size)):
to_send = []
trakt_ids = df["trakt_id"][x:x+batch_size].tolist()
sentences = df["combined_text"][x:x+batch_size].tolist()
embeddings = model.encode(sentences)
for idx, value in enumerate(trakt_ids):
to_send.append(
(
str(value), embeddings[idx].tolist()
))
index.upsert(to_send)
That's it!
Interacting with Vectors
We use the trakt_id for the movie as the ID for the vectors and upsert it into the index.
To find similar items, we will first have to map the name of the movie to its trakt_id, get the embeddings we have for that id and then perform a similarity search. It is possible that this additional step of mapping could be avoided by storing information as metadata in the index.
def get_trakt_id(df, title: str):
rec = df[df["title"].str.lower()==movie_name.lower()]
if len(rec.trakt_id.values.tolist()) > 1:
print(f"multiple values found... {len(rec.trakt_id.values)}")
for x in range(len(rec)):
print(f"[{x}] {rec['title'].tolist()[x]} ({rec['year'].tolist()[x]}) - {rec['overview'].tolist()}")
print("===")
z = int(input("Choose No: "))
return rec.trakt_id.values[z]
return rec.trakt_id.values[0]
def get_vector_value(trakt_id: int):
fetch_response = index.fetch(ids=[str(trakt_id)])
return fetch_response["vectors"][str(trakt_id)]["values"]
def query_vectors(vector: list, top_k: int = 20, include_values: bool = False, include_metada: bool = True):
query_response = index.query(
queries=[
(vector),
],
top_k=top_k,
include_values=include_values,
include_metadata=include_metada
)
return query_response
def query2ids(query_response):
trakt_ids = []
for match in query_response["results"][0]["matches"]:
trakt_ids.append(int(match["id"]))
return trakt_ids
def get_deets_by_trakt_id(df, trakt_id: int):
df = df[df["trakt_id"]==trakt_id]
return {
"title": df.title.values[0],
"overview": df.overview.values[0],
"runtime": df.runtime.values[0],
"year": df.year.values[0]
}
Testing it Out
movie_name = "Now You See Me"
movie_trakt_id = get_trakt_id(df, movie_name)
print(movie_trakt_id)
movie_vector = get_vector_value(movie_trakt_id)
movie_queries = query_vectors(movie_vector)
movie_ids = query2ids(movie_queries)
print(movie_ids)
for trakt_id in movie_ids:
deets = get_deets_by_trakt_id(df, trakt_id)
print(f"{deets['title']} ({deets['year']}): {deets['overview']}")
Output:
55786
[55786, 18374, 299592, 662622, 6054, 227458, 139687, 303950, 70000, 129307, 70823, 5766, 23950, 137696, 655723, 32842, 413269, 145994, 197990, 373832]
Now You See Me (2013): An FBI agent and an Interpol detective track a team of illusionists who pull off bank heists during their performances and reward their audiences with the money.
Trapped (1949): U.S. Treasury Department agents go after a ring of counterfeiters.
Brute Sanity (2018): An FBI-trained neuropsychologist teams up with a thief to find a reality-altering device while her insane ex-boss unleashes bizarre traps to stop her.
The Chase (2017): Some FBI agents hunt down a criminal
Surveillance (2008): An FBI agent tracks a serial killer with the help of three of his would-be victims - all of whom have wildly different stories to tell.
Marauders (2016): An untraceable group of elite bank robbers is chased by a suicidal FBI agent who uncovers a deeper purpose behind the robbery-homicides.
Miracles for Sale (1939): A maker of illusions for magicians protects an ingenue likely to be murdered.
Deceptors (2005): A Ghostbusters knock-off where a group of con-artists create bogus monsters to scare up some cash. They run for their lives when real spooks attack.
The Outfit (1993): A renegade FBI agent sparks an explosive mob war between gangster crime lords Legs Diamond and Dutch Schultz.
Bank Alarm (1937): A federal agent learns the gangsters he's been investigating have kidnapped his sister.
The Courier (2012): A shady FBI agent recruits a courier to deliver a mysterious package to a vengeful master criminal who has recently resurfaced with a diabolical plan.
After the Sunset (2004): An FBI agent is suspicious of two master thieves, quietly enjoying their retirement near what may - or may not - be the biggest score of their careers.
Down Three Dark Streets (1954): An FBI Agent takes on the three unrelated cases of a dead agent to track down his killer.
The Executioner (1970): A British intelligence agent must track down a fellow spy suspected of being a double agent.
Ace of Cactus Range (1924): A Secret Service agent goes undercover to unmask the leader of a gang of diamond thieves.
Firepower (1979): A mercenary is hired by the FBI to track down a powerful recluse criminal, a woman is also trying to track him down for her own personal vendetta.
Heroes & Villains (2018): an FBI agent chases a thug to great tunes
Federal Fugitives (1941): A government agent goes undercover in order to apprehend a saboteur who caused a plane crash.
Hell on Earth (2012): An FBI Agent on the trail of a group of drug traffickers learns that their corruption runs deeper than she ever imagined, and finds herself in a supernatural - and deadly - situation.
Spies (2015): A secret agent must perform a heist without time on his side
For now, I am happy with the recommendations.
Simple UI
The code for the flask app can be found on GitHub: navanchauhan/FlixRec or on my Gitea instance
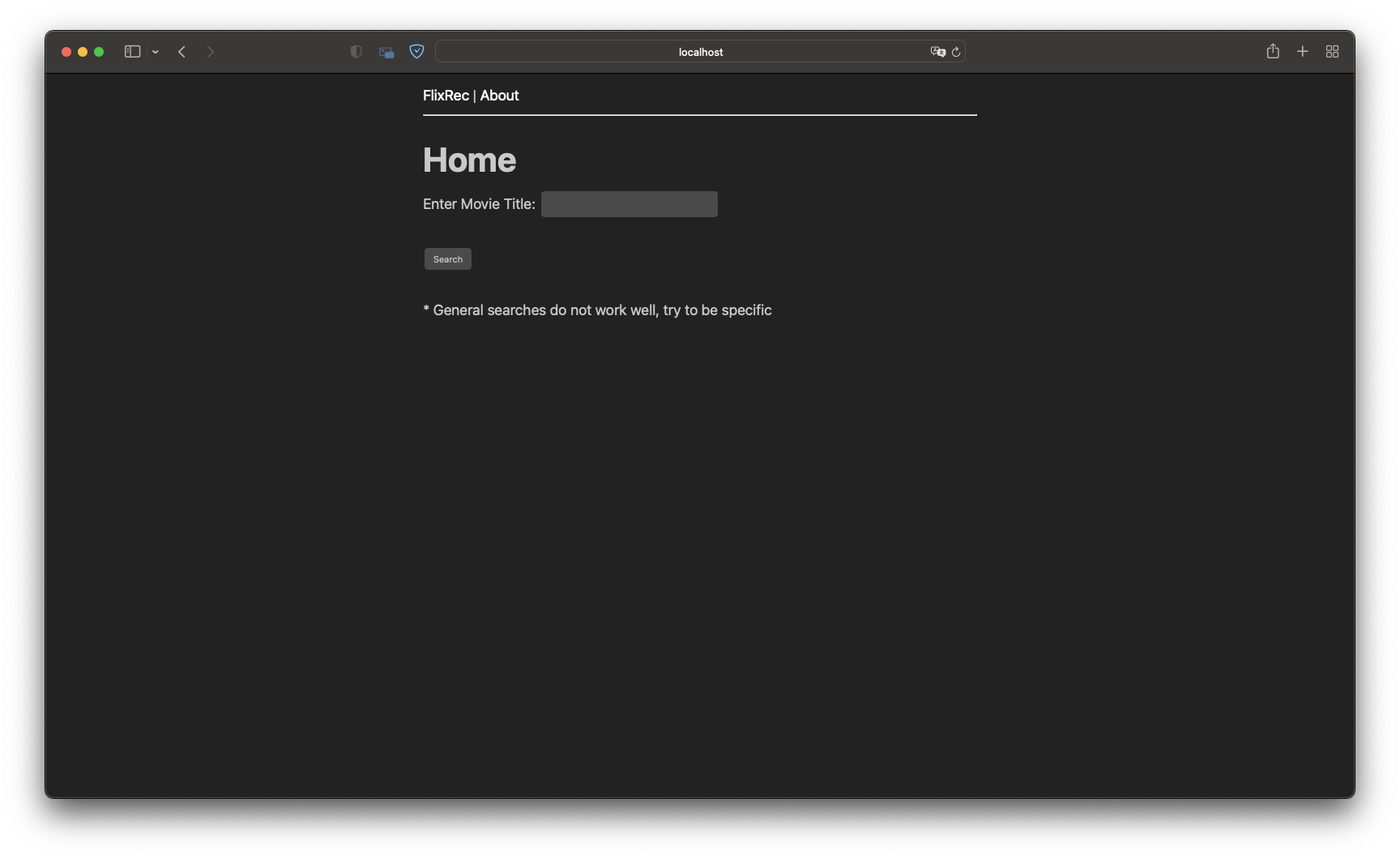
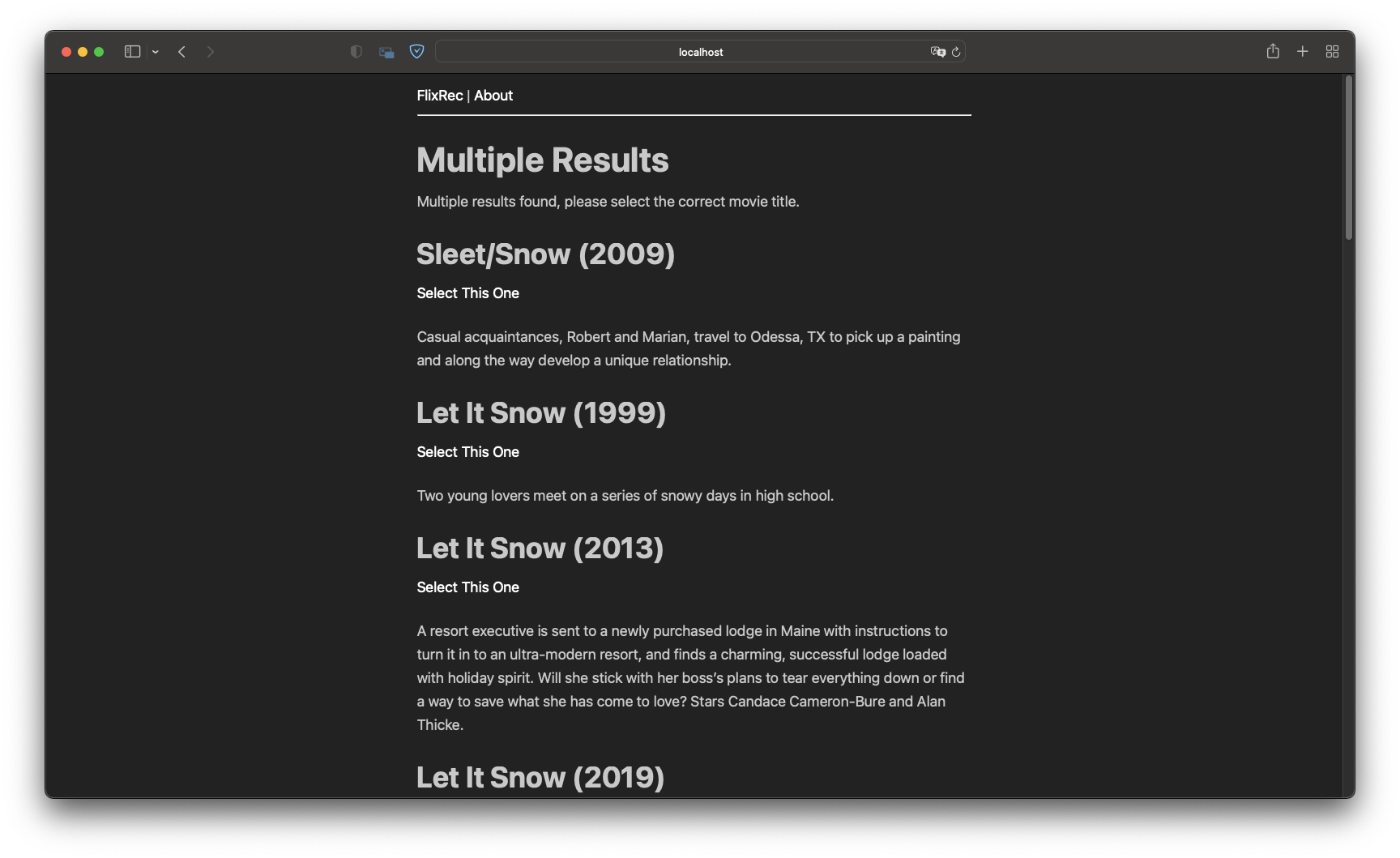
I quickly whipped up a simple Flask App to deal with problems of multiple movies sharing the title, and typos in the search query.
Home Page
Handling Multiple Movies with Same Title
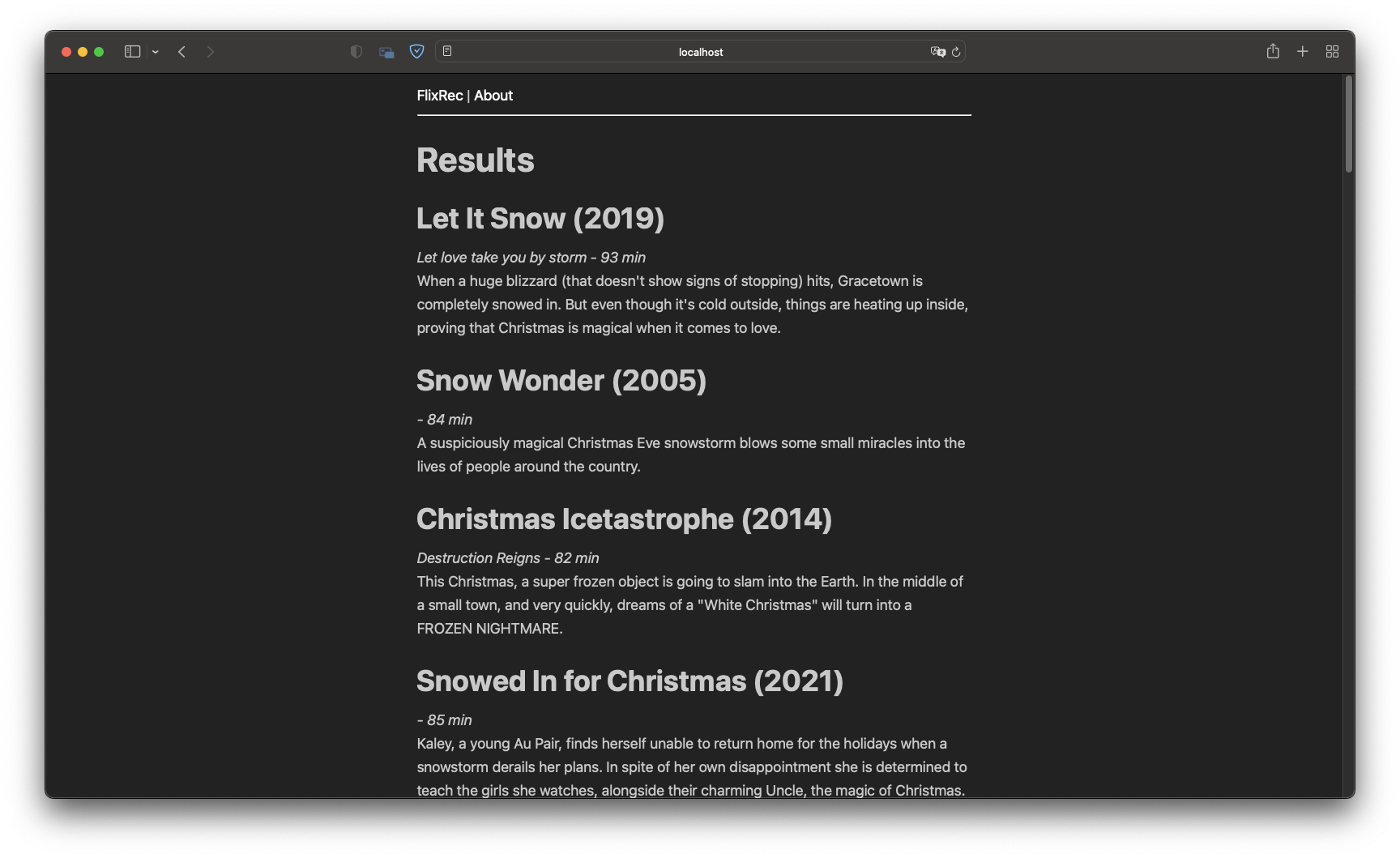
Results Page
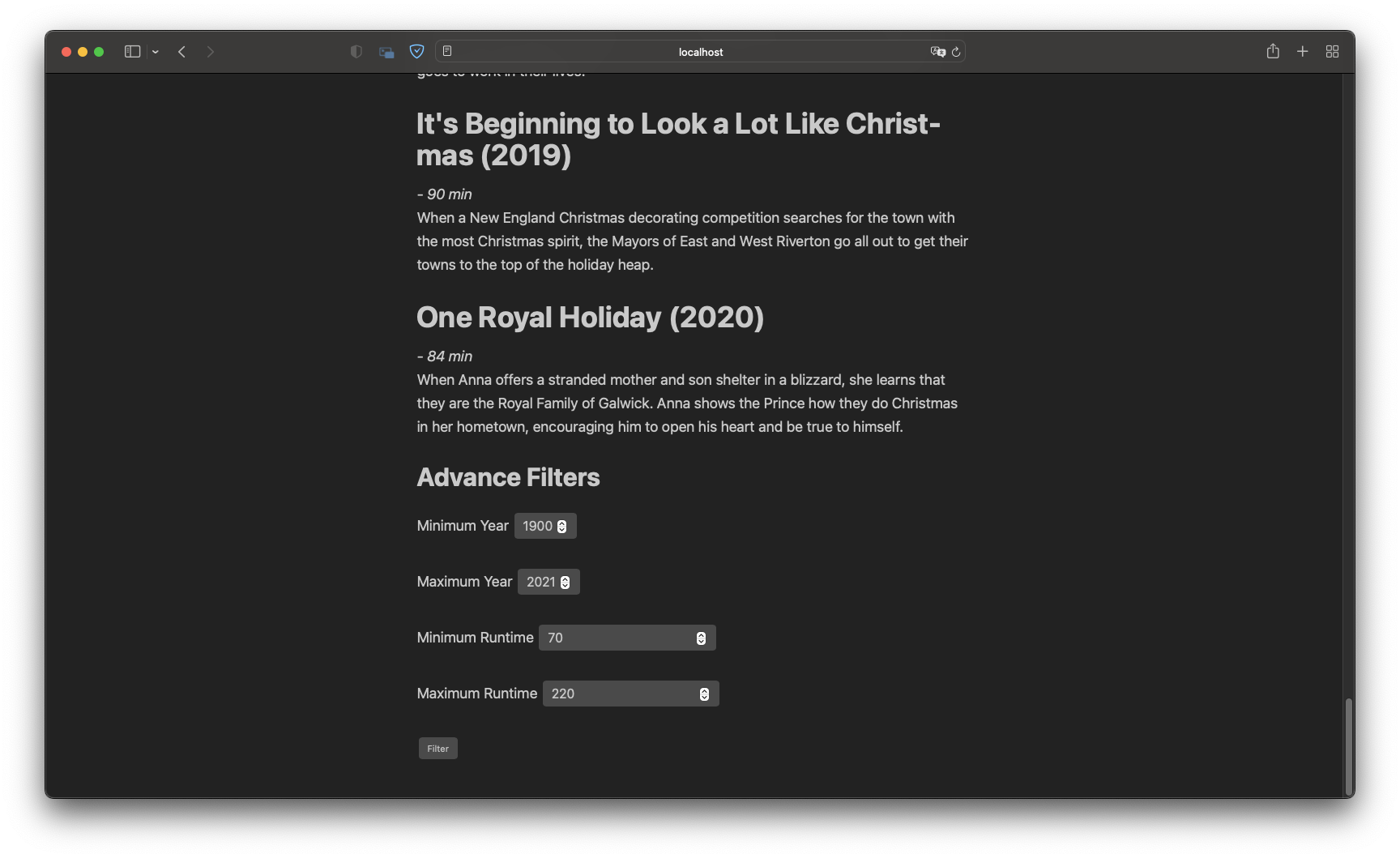
Includes additional filter options
Test it out at https://flixrec.navan.dev
Current Limittations
- Does not work well with popular franchises
- No Genre Filter
Future Addons
- Include Cast Data
- e.g. If it sees a movie with Tom Hanks and Meg Ryan, then it will boost similar movies including them
- e.g. If it sees the movie has been directed my McG, then it will boost similar movies directed by them
- REST API
- TV Shows
- Multilingual database
- Filter based on popularity: The data already exists in the indexed database
